
Transient Failures
A sync can fail for all sorts of reasons. Maybe there’s a network outage, maybe one of the processes managing the sync ran out of memory, or perhaps someone rebooted a router. Whatever the reason, it is impractical to think that a sync lasting a few hours moving terabytes of data won’t have some interruption. Airbyte’s job is to make sure your data continues to flow, even through these interruptions, and we do that through a process called checkpointing. Checkpointing is powerful because it means we can sync any volume of data, given enough time and retries.
What is checkpointing?
Checkpointing is a mechanism which the Airbyte Platform uses to resume any incremental sync from where it left off in the previous attempt. Over the past year, we have been working to ensure that all the parts of Airbyte, our Sources, Platform, and Destinations can work in concert to support checkpointing. We are proud to share that today any source which supports incremental syncs is checkpointable (totally a real word), as are all of our cloud data warehouse destinations, including Snowflake, BigQuery, and Redshift. Our traditional SQL destinations (MySQL, Postgres, etc) and s3 also support checkpointing, with more destinations on the way.
Airbyte’s checkpointing target is that no more than 30 minutes will pass without a checkpoint. That means no more than 30 minutes of sync time will need to be replayed on the next sync attempt if the sync were to fail. Checkpointing is only valid for connections which support incremental syncs, because it relies on asking the source to begin the next sync from a previous state. 30 minutes is the upper boundary, and many sources emit state messages more rapidly, often every time they paginate an API, or adjust limit or offset in a query. Destinations on the other hand have a fine line to walk - they need to balance efficiently writing to the destination with a guarantee to hit that 30 minute mark. For example, we use staging files to upload data to Snowflake, rather than INSERT queries directly, because it is (usually) faster. But, because there’s a cost to every time we upload a file and ask Snowflake to insert it, our destinations balance rapid checkpoints with efficient writes.
How does checkpointing work?
So how does checkpointing work? The Airbyte Protocol of course! Consider the following sync:
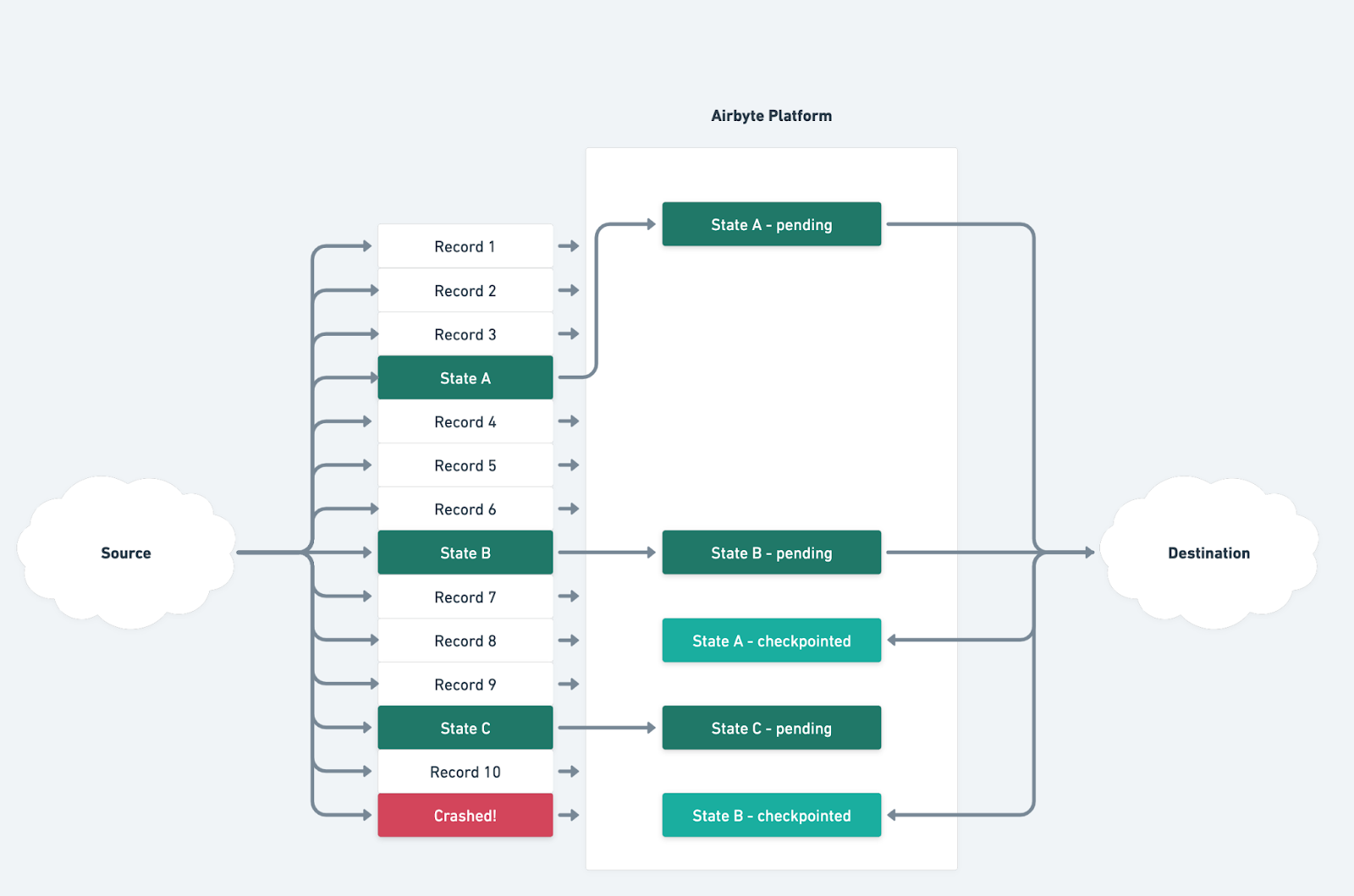
In this example, the source sent 10 records and 3 state messages though the Airbyte platform before crashing. Checkpointing works on STATE messages. If a source sends a state message out, and the destination echos that same state message back to the platform, that means “I have committed all the records the source gave me up to this point”. So, when the destination sends back State message A, that means that it has saved Record 1, Record 2, and Record 3 (e.g. persisted it in the destination database or uploaded it to S3 - whatever “persisting” means to that destination). Only at this point, when the destination confirms that the data is saved on its end, do we have a checkpoint.
In this example where State B was checkpointed but not State C, that means we have checkpointed up to Record 6. The next time we run this sync, we will start at State B, meaning we can skip records 1 through 5, and start with record 7, saving both time and money. Observant readers will note that this will result in the last few records being sent more than once, which is by design - Airbyte is an “at least once” delivery platform. But don’t worry, many of our destinations have additional features, like deduplication, to clean up data on the other side. That’s one of the many neat things about an ELT pipeline - moving the data and cleaning the data happen independently! This allowed Airbyte to choose speed and reliability over “at most once” delivery of records.
What’s next?
So what’s next? Airbyte will continue to add checkpointing to our destinations as they reach the Generally Available release stage. Also, now that our cloud data warehouse destinations are resilient to failure, we are speeding them up! We are also making the tables we produce more intuitive and able to recover from problematic data - learn more about this work here.
Keep on Syncing!