Update (12/18/2012)
These ideas have now been formally incorporated into the actionHero project. To learn how to launch actionHero in a clustered way, check out the wiki.
Update (12/5/2012)
While other servers also use SIGWINCH to mean "kill all my workers" it’s important to note that this signal is fired when you resize your terminal window (responsive console design anyone?). Be sure that only demonized/background process respond to SIGWINCH!
Introduction
I was asked recently how to deploy actionHero to production. Initially, my naive answer was to simply suggest the use of forever, but that was only a partial solution. Forever is a great package which acts as a sort of Deamon-izer for your projects. It can monitor running apps and restart them, handle stdout/err and logging, etc. It’s a great monitoring solution, but when you say forever restart myApp you will incur some downtime. I’ve spent the past few days working on a full solution.
Footnote — This is a *nix (osx/linux/solaris) answer only. I’m fairly sure this kind of thing won’t work on windows.
At TaskRabbit (a Ruby/Rails Ecosystem) we have put in a lot of effort into "properly" implementing Capistrano and Unicorn so that we can have 0-downtime deployment. This is integral to our culture, and allows us to deploy worry-free a number of times each day. This also makes the code-delta in our deployments smaller, and therefore less risky (saying nothing of the value in reducing the time it takes to launch new features). 0-downtime deployments are good.
Framework
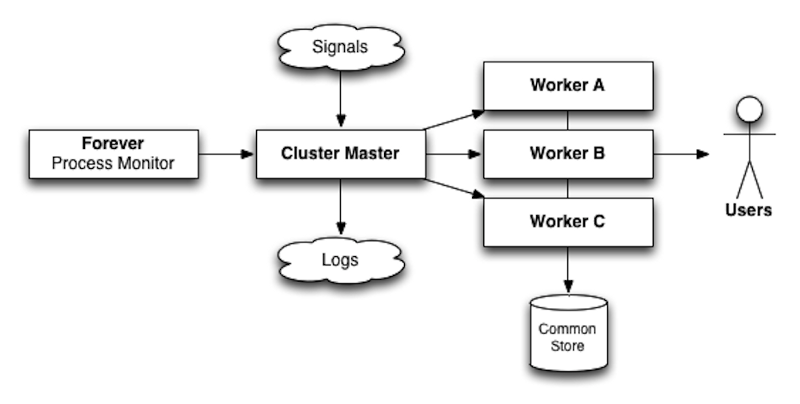
Ok, so how to make a 0-downtime node deployment? Forever is certainly part of the solution, but the meat of the answer lies in the node.js cluster module (and how awesome node is at being unix-y).
The cluster module allows one node process to spawn children and share open recourses with them. This might include file pointers, but in our case, we are going to share open ports and unix sockets. In a nutshell, if you have one worker open port 80, other workers can also listen on port 80. The cluster module will share the load between all available workers.
The cluster module is usually approached as a way to load balance an application (and it’s great at that), but it also can be used as a way to hand over an open connection from one worker to another. In this way, we can tell one worker to die off while another is starting. With enough workers running (and some basic callbacks), we can ensure that there is always a worker around to handle any incoming requests
Application Considerations
This is some core node magic right here. Whether you have created an HTTP server or a direct TCP server, the default behavior of server.close() is actually quite graceful by default. Check out the docs and you sill see that the server will close, but not kick out any existing connections, and finally when all clients have left, a callback is fired. We will be waiting for this callback to know that it is safe to close out our server.
For an HTTP server this is pretty straight forward: no new connections will be allowed in, and any long-lasting connections will have the chance to finish. In our cluster setup, that means that any new connections that come in during this time will be passed to another worker… exactly what we want! (note: it’s possible that a connection might not ever finish, but that’s out of scope for this discussion)
Raw TCP connections are another matter. The server behaves the same way, but TCP connections never really expire, so if we don’t kick out existing connections, the server will never exit. Take a look at this snippit of code from actionHero’s socketServer:
api.socketServer.gracefulShutdown = function (api, next, alreadyShutdown) {
if (alreadyShutdown == null) {
alreadyShutdown = false;
}
if (alreadyShutdown == false) {
api.socketServer.server.close();
alreadyShutdown = true;
}
for (var i in api.socketServer.connections) {
var connection = api.socketServer.connections[i];
if (connection.responsesWaitingCount == 0) {
api.socketServer.connections[i].end("Server going down NOW\r\nBye!\r\n");
}
}
if (api.socketServer.connections.length != 0) {
api.log(
"[socket] waiting on shutdown, there are still " +
api.socketServer.connections.length +
" connected clients waiting on a response",
);
setTimeout(function () {
api.socketServer.gracefulShutdown(api, next, alreadyShutdown);
}, 3000);
} else {
next();
}
};In the part of the TCP server that handles incoming requests, we increment the connection’s connection.responseWaitingCount and when the action completes and the response is sent to the client, we decrement it. This way we can approximate the client is "waiting for a response" or not. It’s important to remember that TCP clients can request many actions at the same time (unlike HTTP, where each request can only ever have one response). Note that once a client is deemed fit to disconnect we send a ‘goodbye’ message. The client then is responsible for reconnecting, and they will come back and connect to another worker.
WebSockets work the same way as the TCP server does. Once we disconnect each client, they will reconnect to a new worker node, as the old one has stopped taking connections. socket.io’s browser code is very well written and will reconnect and retry any commands that have failed. socket.io binds to the http server we talked about earlier, so shutting it down will also disconnect all websocket clients.
Now that we have servers that gracefully shut down, how do we use them?
The Cluster Leader
The reason for gracefully disconnecting each client was that we are not going to restart each server, but rather kill it entirely and create a new one. Creating a new worker ensures that each process will load in any new code and have a fresh environment to work within.
The Cluster leader has a few main goals:
- Sharing Resources. We get this for free from the node.js cluster module
- Worker management. This includes restarting them when they fail along with responding to requests to start/stop them
- Responding to Signals. We’ll cover this in a moment, but essentially this is you you communicate with the leader once he is up and running.
- Logging. You gotta’ log the state of your cluster!
Sharing Resources:
As mentioned before, open sockets and ports can be shared (for free) by all children in the cluster. Yay node!
Worker Managment:
The cluster module provides a message passing interface between leader and follower. You can pass anything that can be JSON.stringified (no pointers). We can use these methods to be aware of when a booted worker is ready to accept connections, and conversely, we can tell a worker to begin its graceful shut down process (rather than outright killing the process). Take a look at the worker code at the bottom of the article for more details. Note the use of process.send(msg) within the callbacks for actionHero.start() and actionHero.stop().
Responding to Signals:
Unix signals are the classy way to communicate with a running application. You send them with the kill command, and each signal has a common meaning:
- SIGINT / SIGTERM / SIGKILL Kill the running process, with various degrees of severity. In our application we will treat these all as meaning "kill the leader and all of his workers"
- SIGUSR2 Tell the leader to reload the configuration of his workers. In our cluster, this will mean a rolling restart of each worker one-by-one.
- SIGHUP reload all workers. For us, this will mean instantaneously kill off all workers and start new ones (will lead to potential downtime)
- SIGWINCH kill off all workers
- TTIN / TTOU add a worker / remove a worker
So if you wanted to tell the leader to stop all of his workers (and his pid was 123), you would run kill -s WINCH 123
USR2 is the most interesting case here. While there are ways to "reload configuration" in a running node.js app (flush the module cache, reload all source modules, etc), it’s usually a lot safer just to start up a new app from scratch. I say that we are going to do a "rolling restart" because we literally are going to kill off the first worker, spawn a new one, and repeat. Assuming we have 2 or more workers, this means that there will always be at least one worker around to handle requests. Now this might lead to problems where some workers have an old version of your codebase and some workers have a new version, but usually that is desirable when compared with outright downtime. Oh, and try not to have more workers than you have CPUs!
The main function in charge of these "rolling restarts" is here:
var reloadAWorker = function (next) {
var count = 0;
for (var i in cluster.workers) {
count++;
}
if (workersExpected > count) {
startAWorker();
}
if (workerRestartArray.length > 0) {
var worker = workerRestartArray.pop();
worker.send("stop");
}
};
cluster.on("exit", function (worker, code, signal) {
log("worker " + worker.process.pid + " (#" + worker.id + ") has exited");
setTimeout(reloadAWorker, 1000); // to prevent CPU-splsions if crashing too fast
});When we initialize a rolling restart, we add all workers to the workerRestartArray, and then one-by-one they will be dropped. Note that on every worker’s exit, we run reloadAWorker(). This also ensures that if a worker died due to an error, we will start another one in its place (workersExpected is modified by TTIN and TTOU). The reason for the timeOut is to ensure that if a worker is crashing on boot (perhaps it can’t connect to your database) that the leader isn’t restarting workers are fast as possible… as this would probably lock up your machine.
Deployment Notes
- While your workers will load up new code changes on restart, the cluster leader will not. Unfortunately, you will need to restart it to catch any code changes. Luckily, you can use forever for this to do it quickly. When you restart the leader all of his workers will die off.
- Building from the earlier comment, child process die when the parent dies. That’s just how it is (usually). That means that if for any reason the leader dies (kill, ctrl-c, etc), all of the workers will die too. That’s why it is best to keep the leader’s code base as simple as possible (and separate from the workers). This is also why we use something like forever to monitor it’s uptime and restart it if anything goes wrong
- I’ve talked about using Capistrano to deploy node.js applications before, but there are lots of methods to get your code on the server (fabric, chef, github post-commit hooks, etc). Once your leader is up and running, your deployment really only looks like 1) git pull 2) kill -s USR2 (pid of leader). Yay!
Code
Here is the state of actionHero’s cluster leader code at the time of this post. It’s likely to keep evolving, so you can always check out the latest version on GitHub
Follower
#!/usr/bin/env node
// load in the actionHero class
var actionHero = require(__dirname + "/../api.js").actionHero; // normally if installed by npm: var actionHero = require("actionHero").actionHero;
var cluster = require("cluster");
// if there is no config.js file in the application's root, then actionHero will load in a collection of default params. You can overwrite them with params.configChanges
var params = {};
params.configChanges = {};
// any additional functions you might wish to define to be globally accessable can be added as part of params.initFunction. The api object will be availalbe.
params.initFunction = function (api, next) {
next();
};
// start the server!
var startServer = function (next) {
if (cluster.isWorker) {
process.send("starting");
}
actionHero.start(params, function (api_from_callback) {
api = api_from_callback;
api.log("Boot Sucessful @ worker #" + process.pid, "green");
if (typeof next == "function") {
if (cluster.isWorker) {
process.send("started");
}
next(api);
}
});
};
// handle signals from leader if running in cluster
if (cluster.isWorker) {
process.on("message", function (msg) {
if (msg == "start") {
process.send("starting");
startServer(function () {
process.send("started");
});
}
if (msg == "stop") {
process.send("stopping");
actionHero.stop(function () {
api = null;
process.send("stopped");
process.exit();
});
}
if (msg == "restart") {
process.send("restarting");
actionHero.restart(function (success, api_from_callback) {
api = api_from_callback;
process.send("restarted");
});
}
});
}
// start the server!
startServer(function (api) {
api.log("Successfully Booted!", ["green", "bold"]);
});Leader
#!/usr/bin/env node
//////////////////////////////////////////////////////////////////////////////////////////////////////
//
// TO START IN CONSOLE: `./scripts/actionHeroCluster`
// TO DAMEONIZE: `forever start scripts/actionHeroCluster`
//
// ** Producton-ready actionHero cluster example **
// - workers which die will be restarted
// - maser/manager specific logging
// - pidfile for leader
// - USR2 restarts (graceful reload of workers while handling requets)
// -- Note, socket/websocket clients will be disconnected, but there will always be a worker to handle them
// -- HTTP, HTTPS, and TCP clients will be allowed to finish the action they are working on before the server goes down
// - TTOU and TTIN signals to subtract/add workers
// - WINCH to stop all workers
// - TCP, HTTP(s), and Web-socket clients will all be shared across the cluster
// - Can be run as a daemon or in-console
// -- Lazy Dameon: `nohup ./scripts/actionHeroCluster &`
// -- you may want to explore `forever` as a dameonizing option
//
// * Setting process titles does not work on windows or OSX
//
// This example was heavily inspired by Ruby Unicorns [[ http://unicorn.bogomips.org/ ]]
//
//////////////////////////////////////////////////////////////////////////////////////////////////////
//////////////
// Includes //
//////////////
var fs = require("fs");
var cluster = require("cluster");
var colors = require("colors");
var numCPUs = require("os").cpus().length;
var numWorkers = numCPUs - 2;
if (numWorkers < 2) {
numWorkers = 2;
}
////////////
// config //
////////////
var config = {
// script for workers to run (You probably will be changing this)
exec: __dirname + "/actionHero",
workers: numWorkers,
pidfile: "./cluster_pidfile",
log: process.cwd() + "/log/cluster.log",
title: "actionHero-leader",
workerTitlePrefix: " actionHero-worker",
silent: true, // don't pass stdout/err to the leader
};
/////////
// Log //
/////////
var logHandle = fs.createWriteStream(config.log, { flags: "a" });
var log = function (msg, col) {
var sqlDateTime = function (time) {
if (time == null) {
time = new Date();
}
var dateStr =
padDateDoubleStr(time.getFullYear()) +
"-" +
padDateDoubleStr(1 + time.getMonth()) +
"-" +
padDateDoubleStr(time.getDate()) +
" " +
padDateDoubleStr(time.getHours()) +
":" +
padDateDoubleStr(time.getMinutes()) +
":" +
padDateDoubleStr(time.getSeconds());
return dateStr;
};
var padDateDoubleStr = function (i) {
return i < 10 ? "0" + i : "" + i;
};
msg = sqlDateTime() + " | " + msg;
logHandle.write(msg + "\r\n");
if (typeof col == "string") {
col = [col];
}
for (var i in col) {
msg = colors[col[i]](msg);
}
console.log(msg);
};
////////// // Main // //////////
log(" - STARTING CLUSTER -", ["bold", "green"]);
// set pidFile
if (config.pidfile != null) {
fs.writeFileSync(config.pidfile, process.pid.toString());
}
process.stdin.resume();
process.title = config.title;
var workerRestartArray = [];
// used to trask rolling restarts of workers
var workersExpected = 0;
// signals
process.on("SIGINT", function () {
log("Signal: SIGINT");
workersExpected = 0;
setupShutdown();
});
process.on("SIGTERM", function () {
log("Signal: SIGTERM");
workersExpected = 0;
setupShutdown();
});
process.on("SIGKILL", function () {
log("Signal: SIGKILL");
workersExpected = 0;
setupShutdown();
});
process.on("SIGUSR2", function () {
log("Signal: SIGUSR2");
log("swap out new workers one-by-one");
workerRestartArray = [];
for (var i in cluster.workers) {
workerRestartArray.push(cluster.workers[i]);
}
reloadAWorker();
});
process.on("SIGHUP", function () {
log("Signal: SIGHUP");
log("reload all workers now");
for (var i in cluster.workers) {
var worker = cluster.workers[i];
worker.send("restart");
}
});
process.on("SIGWINCH", function () {
log("Signal: SIGWINCH");
log("stop all workers");
workersExpected = 0;
for (var i in cluster.workers) {
var worker = cluster.workers[i];
worker.send("stop");
}
});
process.on("SIGTTIN", function () {
log("Signal: SIGTTIN");
log("add a worker");
workersExpected++;
startAWorker();
});
process.on("SIGTTOU", function () {
log("Signal: SIGTTOU");
log("remove a worker");
workersExpected--;
for (var i in cluster.workers) {
var worker = cluster.workers[i];
worker.send("stop");
break;
}
});
process.on("exit", function () {
workersExpected = 0;
log("Bye!");
});
// signal helpers
var startAWorker = function () {
worker = cluster.fork();
log("starting worker #" + worker.id);
worker.on("message", function (message) {
if (worker.state != "none") {
log("Message [" + worker.process.pid + "]: " + message);
}
});
};
var setupShutdown = function () {
log("Cluster manager quitting", "red");
log("Stopping each worker...");
for (var i in cluster.workers) {
cluster.workers[i].send("stop");
}
setTimeout(loopUntilNoWorkers, 1000);
};
var loopUntilNoWorkers = function () {
if (cluster.workers.length > 0) {
log("there are still " + cluster.workers.length + " workers...");
setTimeout(loopUntilNoWorkers, 1000);
} else {
log("all workers gone");
if (config.pidfile != null) {
fs.unlinkSync(config.pidfile);
}
process.exit();
}
};
var reloadAWorker = function (next) {
var count = 0;
for (var i in cluster.workers) {
count++;
}
if (workersExpected > count) {
startAWorker();
}
if (workerRestartArray.length > 0) {
var worker = workerRestartArray.pop();
worker.send("stop");
}
};
// Fork it.
cluster.setupleader({
exec: config.exec,
args: process.argv.slice(2),
silent: config.silent,
});
for (var i = 0; i < config.workers; i++) {
workersExpected++;
startAWorker();
}
cluster.on("fork", function (worker) {
log("worker " + worker.process.pid + " (#" + worker.id + ") has spawned");
});
cluster.on("listening", function (worker, address) {});
cluster.on("exit", function (worker, code, signal) {
log("worker " + worker.process.pid + " (#" + worker.id + ") has exited");
setTimeout(reloadAWorker, 1000); // to prevent CPU-splsions if crashing too fast
});Enjoy!