
Makara is a ruby gem which allows your Rails 3.x application to split its database queries based on their contents. The features of Makara include:
- Read/Write splitting across multiple databases
- Failover om slave errors/loss
- Automatic reconnection attempts to lost slaves
- Optional "sticky" connections to master and slaves
- Works with many database types (mysql, postgres, etc)
- Provides a middleware for releasing stuck connections
- Weighted connection pooling for slave priority
Development History
The main www.taskrabbit.com site is a Rails3 application. As we have grown, we have learned a few things about our load profile:
- We have far more reads than writes (over 20x)
- As we have grown, the ratio of reads to writes has remained consistent
- As most of our traffic is read-heavy, it can be a few seconds out of date, but there are some pages/use-cases which require up-to-date information. This includes pages you have just created (Task posting) or content you just edited (profile updates)
- There are only so many interactions any database can handle before it gets SLOW
As TaskRabbit grew, we quickly realized the need to scale our database tier. We don’t yet have the volume of data which would require traditional sharding (and it’s always nicer to have all of your data in one place for analysis if you can), so we wanted to approach scaling our database tier from a replication point-of-view. As noted above, we aren’t write-heavy, especially since we make use of many temporary stores (like on-disk, memcache, riak, and redis), so the added complexity of master-master replication didn’t seem worth the hassle either. We also have a new bus system current being phased in which will further limit writes. This left traditional master-slave replication and scaling.
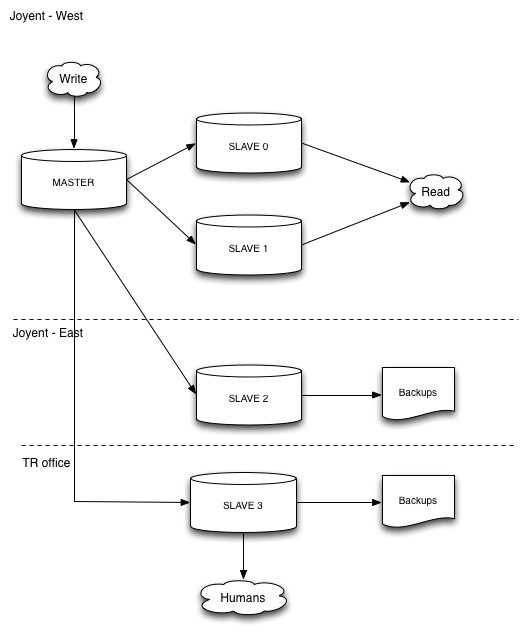
By default, the mysql and mysql2 adaptors for Ruby don’t have any support for more than one database, so we went exploring for other options. Our first stop was the (SoundCloud-specific fork) of the master_slave_adaptor. We used this in production for some time, but we eventually learned that it had a few bugs regarding the way it checked if a slave was up-to-date, and the majority of the time we ended up reading from our master database.
Next we moved on to the Octopus gem (here’s our fork of it). While this gem did allow us to do master-slave splitting, it didn’t handle errors so well. In fact, if any of your slaves went down or timed out, the error bubbled up to your application and presented as a normal database error. While we didn’t solve that within Octopus, we at least were able to introduce the notion of a blacklist (i.e., slaves that went bad) and didn’t use them for subsequent requests after the first user saw the 500 error. After some amount of time had passed, we would check the slave again to see if it came back.
After using Octopus for a while we noticed that, in some rare cases, our web app could be faster than our database replication. For example, if you just posted a Task, the next page we rendered for you is the public Task page so you can confirm that everything looks as you expected. At this point, the INSERT statement that just ran on the master database may not finsihed replicating to the SLAVE(S).If you then query the slave there’s a chance you’ll get a RecordNotFound error. It was this type of error that prompted us to develop the ‘sticky’ notion of choosing a database. In a nutshell, once you have modified a record (INSERT, DELETE, or UPDATE), you should continue to use whichever database you performed that action on for the remainder of your request. This ensures that the data you are using is consistent throughout the request. This notion of sticking was also very important in our Delayed Job workers, which often performed more requests faster than our web servers. Keeping a consistent database is also important when traversing any belongs_to relationships for obvious reasons.
Unfortunately, our logic for this while using the Octopus gem was fairly hacky:
ActiveRecord::ConnectionAdapters::AbstractAdapter.class_eval do
attr_reader :last_query
def log_with_last_query(sql, name, &block)
@last_query = [sql, name]
Octopus::Proxy.master_lock?(sql)
log_without_last_query(sql, name, &block)
end
alias_method_chain :log, :last_query
endYou will notice that because the Octopus gem didn’t expose the actual query Active Record created, we hijacked the logger to get the final query. Octopus made its choices of which type of database to use by inspecting the method called from Active Record rather than query inspection. The way we handled "un-sticking" from a database was to reset it after the request ended in our Unicorn configuration.
We had some trouble upgrading from Rails 2 to Rails 3 with Octopus so we thought it was time to write our own solution.
Features
First and foremost, Makara needed to be able to allow us to scale our database capacity in a way that didn’t require us to change any code within our application (other than a database.yml update). We needed the application to be able to perform on a development laptop running vanilla mySQL and in production with n-geography-specific replication shards. The gem also needed to be able to handle the assignment of roles to these databases. Thus, the structure of our ideal database.yml was born:
production:
sticky_slave: true
sticky_master: true
adapter: makara
db_adapter: mysql2
host: xxx
user: xxx
password: xxx
blacklist_duration: 5
databases:
- name: master
role: master
- name: slave1
role: slave
host: xxx
user: xxx
password: xxx
weight: 3
- name: slave2
role: slave
host: xxx
user: xxx
weight: 2You will note that you can define "common" connection parameters (like a database name), and overwrite them or provide specifics for each replica (for example in production we have a read+write user for master, and a read+only user for the slaves).
The database.yml is structured the same as the underlying connection infrastructure. We have one top-level makara adapter which serves a single purpose: delegating the execution of sql to the best underlying adapter. The underlying adapters are your standard adapters (mysql2, sqlite3, postgresql, etc) with some ruby magic sprinkled on top. The ruby magic isn’t that magical, it’s merely some instance extending which overrides the execute() method, giving the top-level makara adapter the chance to re-route the execution.
On to blacklisting. Because we have inserted ourselves as the Active Record adaptor directly, we have the luxury of actually catching errors from the "real" database adaptors we hold connections to. This made the creation of the blacklist a lot simpler. We can simply hold an array of all the connection pools, and choose which types of errors to catch, and which types to pass though. This also allows us to retry a failed query before passing the results back up to the rest of the Rails stack. Did your read from SLAVE2 just fail because it is under heavy load? It’s cool, lets try it on SLAVE1 and then MASTER. Now if your master databases fails, you have problems, but no gem can save you from that 😄, unless you are running in master-master mode, then we have your back again. There are types of errors (like duplicate key warnings etc) which you do want to bubble up, so we have methods to pass those back to the stack.
We made the choice to be a Rails-only gem, that allowed us to make use of a middleware that helped us enforce our ‘stickiness’ across requests. We ensured that only one slave was used for all queries in a request by default, adn f your wrote to master, you stayed there for the subsequent request. What about the case where you create a new record in one request, and then instantly want to view it in the next? How can you be sure that whichever slave you hit next has the data you need? With a cookie! We use the rails middleware to drop down a cookie if you have been stuck to master, and on the next request, Makara will ensure that you come back to that same database, just for that next request.