
Introduction
At TaskRabbit we use Ansible to configure and manage our servers. Ansible is a great tool which allows you write easy-to-use playbooks to configure your servers, deploy your applications, and more. The "More" part was what led us to switch from Chef to Ansbile. While both tools can have a "provision" action, you can make playbooks for all sorts of things with Ansible, including application deployment!
For the past 4 years, TaskRabbit was using Capistrano to deploy our Rails applications. We built a robust and feature-rich set of plugins which:
- changed the way we logged during deployments (better timestamps, shared the deployment logs with the rest of the team, etc)
- became a rails module we could plug into each of our applications with minimal configuration changes
- standardized some of our deployment steps
- and codified our best practices (ie: cap staging deploy:migrations should work for all apps; All apps should wait for the Unicorns to reboot before clearing cache, etc)
Eventually, we started adding more and more non-rails (Sinatra), and then non-ruby (Node.js) apps. I’ve written before on how you can use Capistrano to deploy anything, including node.js applications. That said, at some point having a ruby dependency for a 500K node app seems silly… but at least we were consistent and clear how all of our projects were to be deployed. Any developer in the company, even if they never touched a line of node before, knew how the app was to be deployed to production.
Then came Ansible.
One of the things that always irked me about Capistrano was that it required duplication of data. Why do I need to keep a list of servers and roles in a deploy.rb file within each application when the authoritative source for that data is our provisioning tool (previously Chef-Server, now the ansible project’s inventory)? Doubly so, every time we added or removed a node from chef, I need to be sure to update the deploy.rb. There are some tools out there which attempt to link Chef and Capistrano, but none of the ones I tried worked. More worrisome was the fact that some of the steps for deployment were duplicated in chef, or Chef was shelling out to Capistrano (which required a full ruby environment) to deploy.
I’m happy to say that TaskRabbit now deploys all of our applications via Ansible, and no longer uses Capistrano. We were able to keep a homogenous command set and duplicate most of Capistrano’s features in very small amount of code. Here’s how we did it:
Server Background
- We deploy on Ubuntu 14 TLS servers.
- We have a specific user, denoted by `` in these roles.
- Our application directory structure exactly mirrors that of Capistrano (it’s a great layout), IE:
/home/{{ deploy_user }}/www/{{ application }}/
- current (symlink to release)
- releases
- timestamp_1
- app
- config (symlinks to ../../shared/config)
- tmp (symlink to ../../shared/tmp)
- pids (symlink to ../../shared/pids)
- timestamp_2
- timestamp_3
- shared
- tmp
- config (ymls and other config files previously config'd by ansible)
- public
- cached-copy (git repo in fullt)
- logs
- pids
- socketsWe define inventories by RAILS_ENV (or NODE_ENV as the case may be), and then divide up each application to the sub-roles that it requires. I’ll be using the following example inventories/production file as reference:
myApp-web1.domain.com
myApp-web2.domain.com
myApp-worker1.domain.com
myApp-worker2.domain.com
myApp-redis.domain.com
myApp-mysql.domain.com
[production]
myApp-web1.domain.com
myApp-web2.domain.com
myApp-worker1.domain.com
myApp-worker2.domain.com
myApp-redis.domain.com
myApp-mysql.domain.com
[production:vars]
rails_env=production
node_env=production
cluster_env=production
[myApp]
myApp-web1.domain.com
myApp-web2.domain.com
myApp-worker1.domain.com
myApp-worker2.domain.com
[myApp:unicorn]
myApp-web1.domain.com
myApp-web2.domain.com
[myApp:resque]
myApp-worker1.domain.com
myApp-worker2.domain.com
# ...Playbook and API
The entry point to our deployment playbook is the deploy.yml playbook:
- hosts: "{{ host | default(application) }}"
max_fail_percentage: 1
roles:
- { role: deploy, tags: ["deploy"], sudo: no }
- { role: monit, tags: ["monit"], sudo: yes }and a rollback.yml playbook:
- hosts: "{{ host | default(application) }}"
max_fail_percentage: 1
tasks:
- include: roles/deploy/tasks/rollback_symlink.yml
- include: roles/deploy/tasks/restart_unicorn.yml
- include: roles/deploy/tasks/restart_resque.ymlThis allows us to have the following API options:
- deploy one app to all staging servers (normal use):
ansible-playbook -i inventories/staging deploy.yml — extra-vars="application=myApp migrate=true"- deploy one app to 1 staging server ( — limit):
ansible-playbook -i inventories/staging deploy.yml — extra-vars="application=myApp migrate=true branch=mybranch" — limit staging-server-1.company.com- deploy myApp production:
ansible-playbook -i inventories/production deploy.yml — extra-vars="application=myApp migrate=true"The beauty of the line — hosts: "" in the playbook is that you can reference the servers in question by the group they belong to, which in our case matches the application names, and then sub-slice the group even further via optional — limit flags.
Variables
To make this playbook work, we need a collection of application metadata. This essentially mirrors the information you would provide within an application’s deploy.rb in Capistrano. However, moving this data to Ansible allows it be used not only in both of the deployment/rollback playbooks, but also in provisioning if needed. Here’s some example data for our myApp application, which we can pretend is a Rails 4 application:
From group_vars/all
applications:
- myApp
- myOtherApp
application_git_url_base: git@github.com
application_git_url_team: myCompany
deploy_email_to: everyone@myCompany.com
application_configs:
myApp:
name: myApp
language: ruby
roles:
- unicorn
- resque
ymls:
- database.yml
- memcache.yml
- redis.yml
- facebook.yml
- s3.yml
- twilio.yml
pre_deploy_tasks:
- { cmd: "bundle exec rake assets:precompile" }
- { cmd: "bundle exec rake db:migrate", run_once: true, control: migrate }
- { cmd: "bundle exec rake db:seed", run_once: true, control: migrate }
- { cmd: "bundle exec rake myApp:customTask" }
post_deploy_tasks:
- { cmd: "bundle exec rake cache:clear", run_once: true }
- { cmd: "bundle exec rake bugsnag:deploy", run_once: true }
resque_workers:
- name: myApp
workers:
- { name: myApp-scheduler, cmd: "resque:scheduler" }
- { name: myApp-1, cmd: "resque:queues resque:work" }
- { name: myApp-2, cmd: "resque:queues resque:work" }
#...You can see here that we have defined a few things:
- the configuration files needed for each app (that we place in /home//www//shared/config as noted above)
- metadata about the application, including the language (ruby) and the roles (unicorn and resque)
- tasks to complete before and after the "deploy". The moment the "deploy" happens here is when the symlink for the current symlink switches over.
The Role: Deploy
roles/deploy/main.yml Looks like this:
- include: init.yml
- include: git.yml
- include: links.yml
- include: config.yml
- include: bundle.yml
- include: pre_tasks.yml
- include: reboot.yml
- include: post_tasks.yml
- include: cleanup.yml
- include: email.yml
- include: hipchat.ymlLets go through each step 1-by-1:
init.yml
- name: Generate release timestamp
command: date +%Y%m%d%H%M%S
register: timestamp
run_once: true
- set_fact: "release_path='/home/{{ deploy_user }}/www/{{ application }}/releases/{{ timestamp.stdout }}'"
- set_fact: "shared_path='/home/{{ deploy_user }}/www/{{ application }}/shared'"
- set_fact: "current_path='/home/{{ deploy_user }}/www/{{ application }}/current'"
- set_fact: migrate={{ migrate|bool }}
when: migrate is defined
- set_fact: migrate=false
when: migrate is not defined
- set_fact: branch=master
when: branch is not defined and cluster_env != 'production'
- set_fact: branch=production
when: cluster_env == 'production'
- set_fact: keep_releases={{ keep_releases|int }}
when: keep_releases is defined
- set_fact: keep_releases={{ 6|int }}
when: keep_releases is not defined
- name: "capture previous git sha"
run_once: true
register: deploy_previous_git_sha
shell: >
cd {{ current_path }} &&
git rev-parse HEAD
ignore_errors: trueYou can see that we do a few things: — generate the release timestamp on server to use on all of them — save the paths release_path, shared_path and current_path, just like Capistrano — handle default values for the migrate, branch, and keep_releases options — learn the git SHA of the previous release
git.yml
- name: update source git repo
shell: "git fetch && git reset --hard origin/master"
sudo: yes
sudo_user: "{{ deploy_user }}"
args:
chdir: "{{ shared_path }}/cached-copy"
when: "'{{application}}' in group_names"
- name: Create release directory
file: "state=directory owner='{{ deploy_user }}' path='{{ release_path }}'"
sudo: yes
sudo_user: "{{ deploy_user }}"
when: "'{{application}}' in group_names"
- name: copy the cached git copy
shell: "cp -r {{ shared_path }}/cached-copy/. {{ release_path }}"
sudo: yes
sudo_user: "{{ deploy_user }}"
when: "'{{application}}' in group_names"
- name: git checkout
shell: "git checkout {{ branch }}"
sudo: yes
sudo_user: "{{ deploy_user }}"
args:
chdir: "{{ release_path }}"
when: "'{{application}}' in group_names"This section ensure that we git-pull the latest code into the cached-copy, copy it into the new release_directory, and then checkout the proper branch
links.yml
- name: ensure directories
file: "path={{ release_path }}/{{ item }} state=directory"
sudo: yes
sudo_user: "{{ deploy_user }}"
when: "'{{application}}' in group_names"
with_items:
- tmp
- public
- name: symlinks
shell: "rm -rf {{ item.dest }} && ln -s {{ item.src }} {{ item.dest }}"
sudo: yes
sudo_user: "{{ deploy_user }}"
when: "'{{application}}' in group_names"
with_items:
- { src: "{{ shared_path }}/log", dest: "{{ release_path }}/log" }
- { src: "{{ shared_path }}/pids", dest: "{{ release_path }}/tmp/pids" }
- { src: "{{ shared_path }}/pids", dest: "{{ release_path }}/pids" } #Note: Double symlink for node apps
- {
src: "{{ shared_path }}/sockets",
dest: "{{ release_path }}/tmp/sockets",
}
- {
src: "{{ shared_path }}/assets",
dest: "{{ release_path }}/public/assets",
}
- {
src: "{{ shared_path }}/system",
dest: "{{ release_path }}/public/system",
}This creates symlinks from each deployed release back to shared. This enables us to save logs, pids, etc between deploys.
config.yml
- name: list shared config files
shell: "ls -1 {{ shared_path }}/config"
register: remote_configs
when: "'{{application}}' in group_names"
- name: symlink configs
shell: "rm -f {{ release_path }}/config/{{ item }} && ln -s {{ shared_path }}/config/{{ item }} {{ release_path }}/config/{{ item }} "
with_items: remote_configs.stdout_lines
sudo: yes
sudo_user: "{{ deploy_user }}"
when: "'{{application}}' in group_names"Here we source every file in app/shared/config/* and symlink it into app/release/config/*
bundle.yml
- stat: path={{ release_path }}/Gemfile
register: deploy_gemfile_exists
- name: bundle install
sudo: yes
sudo_user: "{{ deploy_user }}"
args:
chdir: "{{ release_path }}"
shell: >
bundle install
--gemfile {{ release_path }}/Gemfile
--path {{ shared_path }}/bundle
--without development test
--deployment --quiet
when: "'{{application}}' in group_names and deploy_gemfile_exists.stat.exists"If there is a Gemfile in this project, we bundle install
pre_tasks.yml
- name: deployment pre tasks (all hosts)
sudo: yes
sudo_user: "{{ deploy_user }}"
shell: >
cd {{ release_path }} &&
RAILS_ENV={{ rails_env }}
RACK_ENV={{ rails_env }}
NODE_ENV={{ rails_env }}
{{ item.cmd }}
run_once: false
when: >
('{{application}}' in group_names) and
({{ item.run_once | default(false) }} == false) and
({{ item.control | default(true) }} != false)
with_items: "application_configs[application].pre_deploy_tasks"
- name: deployment pre tasks (single hosts)
sudo: yes
sudo_user: "{{ deploy_user }}"
shell: >
cd {{ release_path }} &&
RAILS_ENV={{ rails_env }}
RACK_ENV={{ rails_env }}
NODE_ENV={{ rails_env }}
{{ item.cmd }}
run_once: true
when: >
('{{application}}' in group_names) and
({{ item.run_once | default(false) }} == true) and
({{ item.control | default(true) }} != false)
with_items: "application_configs[application].pre_deploy_tasks"In the application_configs part of our variable file, we defined a collection of tasks to run as part of the deploy. Here is where asset compilation would be run, etc. Note how when you define the task, we have the attributes "run_once" and "control", IE: { cmd: "bundle exec rake db:migrate", run_once: true, control: migrate }. This means that the migration task should only be run on one host, and that it should only be run when the playbook is run with the flags — extra-vars=’migrate=true’. This is how simple it is to build complex Capistrano-like roles.
reboot.yml
- name: Update current Symlink
sudo: yes
sudo_user: "{{ deploy_user }}"
file: "state=link path={{ current_path }} src={{ release_path }}"
notify:
- deploy restart unicorn
- deploy restart resque
when: "'{{application}}' in group_names"
- meta: flush_handlersNow that all of our pre-tasks have been run, it’s time to actually change the deploy symlink and "restart" our applications. This simple role just changes the symlink, but the notifications are fairly involved. Some of your servers (Unicorn) may be able to gracefully restart with a simple signal, while others (like resque workers) need to fully stop and start to accept new code. Ansible makes it easy to build notification handlers that fit your needs:
handlers/main.yml
## UNICORN ##
- name: "deploy restart unicorn"
when: "'unicorn' in application_configs[application].roles and '{{application}}:unicorn' in group_names"
ignore_errors: yes
shell: "kill -s USR2 `cat {{ current_path }}/tmp/pids/unicorn.pid`"
sudo: yes
sudo_user: "{{ deploy_user }}"
notify:
- ensure monit monitoring unicorn
- name: ensure monit monitoring unicorn
monit:
name: unicorn-{{ application }}
state: monitored
sudo: yes
## RESQUE ##
- name: deploy restart resque
ignore_errors: yes
shell: "kill -s QUIT `cat {{ current_path }}/tmp/pids/resque-resque-{{ item.0.name }}-{{ item.1.name }}.pid`"
with_subelements:
- resque_workers
- workers
when: "'{{ item.0.name }}:resque' in group_names and item.0.name == application"
notify: ensure monit monitoring resque
sudo: yes
- name: ensure monit monitoring resque
monit:
name: "resque-{{ item.0.name }}-{{ item.1.name}}"
state: monitored
with_subelements:
- resque_workers
- workers
when: "'{{ item.0.name }}:resque' in group_names and item.0.name == application"
notify: reload monit
sudo: yesYou can see here that we chain notification handlers here to both restart the application and then ensure that our process monitor, monit, is configured to watch that application.
post_tasks.yml
- name: deployment post tasks (all hosts)
sudo: yes
sudo_user: "{{ deploy_user }}"
shell: >
cd {{ release_path }} &&
RAILS_ENV={{ rails_env }}
RACK_ENV={{ rails_env }}
NODE_ENV={{ rails_env }}
{{ item.cmd }}
run_once: false
when: >
('{{application}}' in group_names) and
({{ item.run_once | default(false) }} == false) and
({{ item.control | default(true) }} != false)
with_items: "application_configs[application].post_deploy_tasks"
- name: deployment post tasks (single hosts)
sudo: yes
sudo_user: "{{ deploy_user }}"
shell: >
cd {{ release_path }} &&
RAILS_ENV={{ rails_env }}
RACK_ENV={{ rails_env }}
NODE_ENV={{ rails_env }}
{{ item.cmd }}
run_once: true
when: >
('{{application}}' in group_names) and
({{ item.run_once | default(false) }} == true) and
({{ item.control | default(true) }} != false)
with_items: "application_configs[application].post_deploy_tasks"post_tasks are just like pre_tasks, and allow you to run code after the servers have been restarted. Here is where you might clear caches, update CDNs, etc.
email.yml
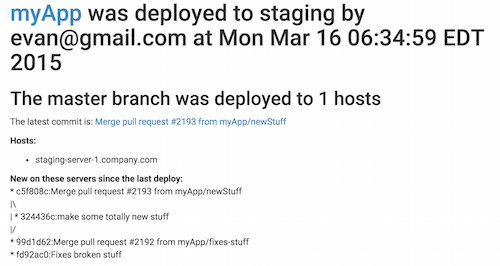
Now the fun kicks in. Ansible makes it easy to keep adding more to your playbooks. We wanted to send the development team an email (and also notify hipchat in a similar role) every time a deploy goes out. Here’s a sample:
Here’s how to grab the variables you need:
- name: "capture: sha"
run_once: true
register: deploy_email_git_sha
shell: >
cd {{ release_path }} &&
git rev-parse HEAD
- name: "capture: deployer_email"
run_once: true
register: deploy_email_deployer_email
shell: >
cd {{ release_path }} &&
git log -1 --pretty="%ce"
- name: "capture: branch"
run_once: true
register: deploy_email_branch
shell: >
cd {{ release_path }} &&
git rev-parse --abbrev-ref HEAD
- name: "capture: commit message"
run_once: true
register: deploy_email_commit_message
shell: >
cd {{ release_path }} &&
git log -1 --pretty="%s"
- set_fact: previous_revision='n/a'
when: previous_revision is defined
- name: "capture: previous commits"
run_once: true
register: deploy_email_previous_commits
when: deploy_previous_git_sha is defined and ( deploy_previous_git_sha.stdout_lines | length > 0 )
shell: >
cd {{ release_path }} &&
git log {{ deploy_previous_git_sha.stdout_lines[0] }}..{{ deploy_email_git_sha.stdout_lines[0] }} --pretty=format:%h:%s --graph
- name: "capture: human date"
run_once: true
register: deploy_email_human_date
shell: date
- name: build the deploy email body
run_once: true
local_action: template
args:
src: deploy_email.html.j2
dest: /tmp/deploy_email.html
- name: send the deploy email
run_once: true
when: no_email is not defined or no_email == false
local_action: shell sendmail {{ deploy_email_to }} < /tmp/deploy_email.htmland our email template is:
From: {{ deploy_email_deployer_email.stdout_lines[0] }}
Subject: Deployment: {{ application }} [ {{ cluster_env }} ]
Content-Type: text/html
MIME-Version: 1.0
<h1>
<a href="https://github.com/{{ application_git_url_team }}/{{ application }}">{{ application }}</a>
was deployed to {{ cluster_env }} by {{ deploy_email_deployer_email.stdout_lines[0] }}
at {{ deploy_email_human_date.stdout_lines[0] }}
</h1>
<h2>The {{ deploy_email_branch.stdout_lines[0] }} branch was deployed to {{ vars.play_hosts | count }} hosts</h2>
<p>The latest commit is: <a href="https://github.com/{{ application_git_url_team }}/{{ application }}/commit/{{ deploy_email_git_sha.stdout_lines[0] }}">{{ deploy_email_commit_message.stdout_lines[0] }}</a> </p>
<strong>Hosts:</strong>
<ul>
{% for host in vars.play_hosts %}
<li>{{ host }}</li>
{% endfor %}
</ul>
{% if deploy_email_previous_commits is defined and deploy_previous_git_sha.stdout_lines | length > 0 %}
<strong>New on these servers since the last deploy:</strong>
<br />
{% for line in deploy_email_previous_commits.stdout_lines %}
{{ line }}<br />
{% endfor %}
{% endif %}And that’s how you build Capistrano within Ansible! You can see how simple it is to translate a complex tool into a few hundred lines of Ansible… with very clear responsibilities and separation. It’s also very easy to extend this to fit your workflow.